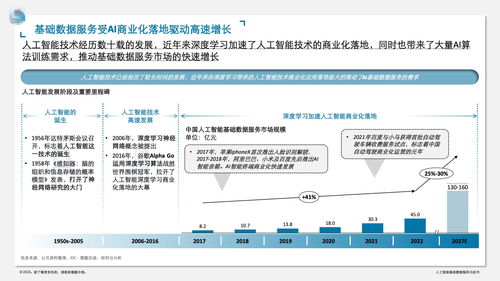
人工智能基础软件的开发是一个复杂且迭代的过程,它不仅依赖于先进的算法和模型,更离不开海量、高质量数据的支持。在利用大数据驱动人工智能(AI)系统构建时,开发者需在技术、伦理和工程实践等多个维度保持高度警惕。以下是开发过程中必须注意的十二个关键点:
- 数据质量与预处理是基石:大数据并非“好数据”。原始数据往往包含噪声、缺失值和不一致性。投入充足资源进行数据清洗、去重、归一化和标注是确保模型性能的第一步。高质量的训练数据直接决定了AI系统的上限。
- 明确问题定义与数据对齐:在收集数据之前,必须清晰定义AI系统要解决的具体业务问题。数据的特征、分布和规模应与问题场景紧密对齐,避免“用锤子找钉子”式的资源浪费。
- 重视数据多样性与代表性:训练数据应尽可能覆盖真实世界的各种场景和边缘案例,以减少模型偏见(Bias)并提高其泛化能力。例如,人脸识别系统的训练数据需要涵盖不同种族、年龄、光照条件和姿态。
- 保障数据安全与隐私合规:在数据采集、存储、传输和处理的全生命周期中,必须严格遵守如GDPR、个人信息保护法等法律法规。采用数据脱敏、差分隐私、联邦学习等技术,在利用数据价值的同时保护用户隐私。
- 构建可扩展的数据管道:设计灵活、高效的数据流水线(Data Pipeline),能够应对数据量的快速增长和来源的多样化。这包括数据的实时/批量摄入、存储、处理和服务化能力。
- 算法与模型的选择与优化:根据问题性质和数据特点,选择合适的机器学习或深度学习模型。避免盲目追求复杂模型,需在模型性能、推理速度、资源消耗和可解释性之间取得平衡。持续进行超参数调优和模型压缩。
- 实现高效的训练与部署:利用分布式计算框架(如Spark、Ray)和专用硬件(如GPU/TPU)加速模型训练。建立模型版本管理、持续集成/持续部署(CI/CD)流程,确保模型能够平滑、可靠地部署到生产环境。
- 建立完善的监控与评估体系:模型上线并非终点。必须建立对模型性能、数据漂移(Data Drift)和概念漂移(Concept Drift)的持续监控机制。使用明确的评估指标(如准确率、召回率、F1分数、AUC等)并定期在独立测试集上验证。
- 确保系统的可解释性与可追溯性:尤其是用于金融、医疗等高风险领域的AI系统,需要具备一定的可解释性。记录模型决策的关键数据依据和逻辑,以便在出现问题时进行追溯和审计,增强用户信任。
- 关注伦理与偏见消除:主动检测并努力消除数据及算法中可能存在的性别、种族、地域等偏见。建立伦理审查机制,确保AI系统的应用符合社会公序良俗,避免产生歧视性后果。
- 促进跨学科团队协作:成功的AI项目需要数据科学家、算法工程师、软件工程师、领域专家(如医生、金融分析师)以及产品经理的紧密合作。确保业务需求与技术实现之间的有效沟通。
- 规划长期维护与迭代路径:人工智能系统需要持续的“喂养”和维护。规划好模型的再训练周期、新数据集成方案以及技术栈的升级路径,以应对不断变化的业务需求和外部环境。
人工智能基础软件的开发是一项系统工程,其成功不仅取决于技术的先进性,更依赖于对数据生命周期的精细管理、对工程最佳实践的遵循以及对伦理风险的审慎考量。将这十二点融入开发流程,将为构建健壮、可靠且负责任的AI系统奠定坚实基础。